¿Qué es... un escáner?
La interfaz TWAIN
Aunque se trata de un tema que compete estrictamente al software (los programas), no viene mal comentar brevemente en qué consiste este elemento. Se trata de una norma que se definió para que cualquier escáner pudiera ser usado por cualquier programa de una forma estandarizada e incluso con la misma interfaz para la adquisición de la imagen.
Si bien hace unos años aún existía un número relativamente alto de aparatos que usaban otros métodos propios, hoy en día se puede decir que todos los escáners normales utilizan este protocolo, con lo que los fabricantes sólo deben preocuparse de proporcionar el controlador TWAIN apropiado, generalmente en versiones para Windows 9x, NT y a veces 3.x. Desgraciadamente, sólo los escáners de marca relativamente caros traen controladores para otros sistemas operativos como OS/2 o Linux, e incluso en ocasiones ni siquiera para Windows 3.x o NT; la buena noticia es que la estandarización de TWAIN hace que a veces podamos usar el controlador de otro escáner de similares características, aunque evidentemente no es un método deseable...
Dejando aparte las librerías DLL y otros temas técnicos, la parte que el usuario ve del estándar TWAIN es la interfaz de adquisición de imágenes. Se trata de un programa en el que de una forma visual podemos controlar todos los parámetros del escaneado (resolución, número de colores, brillo...), además de poder definir el tamaño de la zona que queremos procesar.
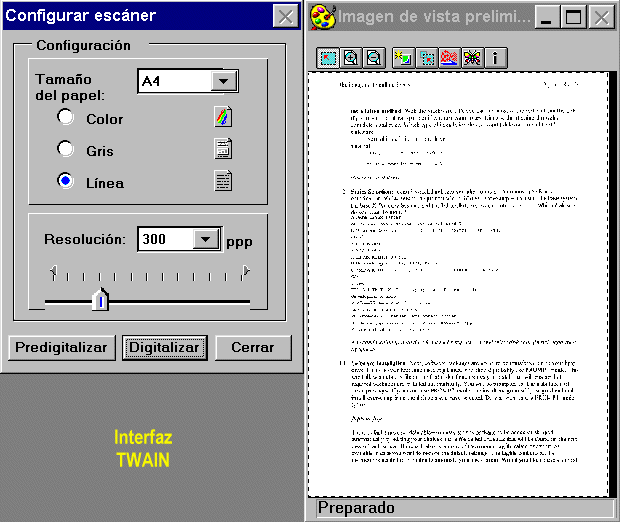
Si la fidelidad del color es un factor de importancia, uno de los parámetros que probablemente deberemos modificar en esta interfaz es el control de gamma, para ajustar la gama de colores que capta el escáner con la que presenta nuestro monitor o imprime la impresora. Le recomiendo que busque en la documentación del escáner para más información.
El OCR
Se trata de una de las aplicaciones más comunes de los escáners. OCR son las siglas de Optical Character Recognition, reconocimiento óptico de caracteres, o con una descripción más sencilla: cómo hacer para enseñar a leer al ordenador.
Si pensamos un poco en el proceso de escaneado que hemos descrito anteriormente, nos daremos cuenta de que al escanear un texto no se escanean letras, palabras y frases, sino sencillamente los puntos que las forman, una especie de fotografía del texto. Evidentemente, esto puede ser útil para archivar textos, pero sería deseable que pudiéramos coger todas esas referencias tan interesantes pero tan pesadas e incorporarlas a nuestro procesador de texto no como una imagen, sino como texto editable.
Lo que desearíamos en definitiva sería que el ordenador supiera leer como nosotros. Bueno, pues eso hace el OCR: es un programa que lee esas imágenes digitales y busca conjuntos de puntos que se asemejen a letras, a caracteres. Dependiendo de la complejidad de dicho programa entenderá más o menos tipos de letra, llegando en algunos casos a interpretar la escritura manual, mantener el formato original (columnas, fotos entre el texto...) o a aplicar reglas gramaticales para aumentar la exactitud del proceso de reconocimiento.
Para que el programa pueda realizar estas tareas con una cierta fiabilidad, sin confundir "t" con "1", por ejemplo, la imagen que le proporcionamos debe cumplir unas ciertas características. Fundamentalmente debe tener una gran resolución, unos 300 ppp para textos con tipos de letra claros o 600 ppp si se trata de tipos de letra pequeños u originales de poca calidad como periódicos. Por contra, podemos ahorrar en el aspecto del color: casi siempre bastará con blanco y negro (1 bit de color), o a lo sumo una escala de 256 grises (8 bits). Por este motivo algunos escáners de rodillo (muy apropiados para este tipo de tareas) carecen de soporte para color.
El equipo necesario
No podemos terminar esta explicación sobre los escáners sin dar unas nociones acerca del hardware imprescindible para manejarlos (y el recomendable, que como siempre es superior a éste... y más caro).
Actualmente, gracias a los formatos de archivo con compresión el almacenaje de las imágenes está totalmente solucionado, sobre todo en esta época de discos duros de 4 GB y más; el problema irresoluble es la memoria RAM necesaria para presentar las imágenes en la pantalla y tratarlas o imprimirlas.
Como hemos dicho en varias ocasiones, no es raro que una imagen ocupe en memoria 25 MB o más; por tanto, en el momento en que superemos la memoria físicamente instalada en el ordenador (hoy en día unos 64 MB, aunque hasta hace bien poco eran 16 MB o incluso menos) el ordenador hará uso de la memoria virtual, que no es sino memoria imitada gracias al disco duro. El problema es que esta "memoria falsa" es muchos miles de veces más lenta que la RAM, lo que puede eternizar el proceso, además de poner al límite de su resistencia al muy inestable Windows 95 (y a su hermano mayor el bastante inestable 98).
Por todo esto, para trabajar con un escáner resulta imprescindible tener al menos 16 MB de RAM, siendo absolutamente necesario llegar hasta los 32 MB si vamos a trabajar habitualmente con originales en color en formatos que superen los 10x15 cm. Y si nuestro objetivo pasa por escanear imágenes A4 o mayores a altas resoluciones (600x600 ppp o más) y luego tratarlas en el ordenador (por ejemplo para autoedición, trabajos de imprenta digitales o pasar a formato electrónico planos de arquitectura o ingeniería), el mínimo absoluto son 64 MB.
Por lo demás, el ordenador no necesita unas prestaciones elevadas; puede bastar con un microprocesador 486, aunque teniendo en cuenta que el tratamiento digital de imágenes es un proceso que aprovecha bastante cualquier aumento de potencia en este sentido. Sea razonable, si se compra un escáner de 12.000 pts no necesitará un Pentium III, pero si se lo compra de 50.000 pts no lo conecte a un ordenador que cueste menos que el escáner...

|
Pulse en el cuadro desplegable o en "Volver" |